So before diving into the blog, I would like to ask you a question:-
1. Do you also feel that with every single year passing your YouTube feed is getting better?
2. Do you also notice that your smartwatch has started giving you better recommendations (month by month) about the exercise schedule you can follow today or the meals can be best for you?
3. The smartphones in your pocket have come miles in just years with regards to AI-powered photography.
I think most of you would answer yes, but do you know what’s common in all of them? These ideas have roots in AI advancement and with great improvements in AI and more demand for personalized content to be served in almost every domain ranging from YouTube feeds to Personalized Workout routines. The market of personalized recommendations is growing like never before and this market brings a new challenge.
The challenge is that these advanced AI algorithms should run on small or better say less power-demanding machines like wristwatches, televisions, etc.
Now to solve this challenge, let’s understand what Quantization is.
By definition, it means - A generic method that points to the compression of data into a smaller space. Though this seems to be intuitive, there is more than meets the eye. Let’s dive in
Here’s a simple illustration of quantization from our daily lives:
We almost all the time use the basic concept of quantization everyday examples are:-
Two friends Jay and John are talking each other:
Jay asks John ‘What’s the time’ John replies that it’s 10:58 pm however he chooses to reply that it’s 11 pm.
Did you notice what happened? John instead of pointing to exact time responded with a broader time bucket, albeit it’s not 100% accurate - and this is a simple example of Quantization.
Now let’s understand the concept of quantization from the perspective of LLM and why it is important.
And yes, please remember quantization is nowhere similar or equal to dimensionality reduction techniques like PCA, TSNE, etc.
In PCA ( Principal component Analysis ) we take in the input vectors, calculate eigenvectors and eigenvalues, and calculate the Principal component. We then check whether the Top-N dimensions can explain the majority of variance. If yes, we conclude that our original vector can be condensed to a lower dimension.
But in quantization, we don’t condense the dimension, but just put the data in the vectors we are dealing with to bigger baskets so that computation can be made easy (we just approximate the values to the nearest integers )
But always remember this
Let me break it further into different types of quantization.
In this approach of quantization, maximum, and minimum are calculated across every dimension for the entire database, and then a split is made in that dimension uniformly creating different equal-sized bins across the entire range.
Let’s take an example to start with:
Say we have a Vector DB of 2000 vectors each having 256 dimensions, and each vector is sampled from Gaussian distribution. Our goal is to perform scalar quantization on this dataset.
Now let’s calculate the start value and step size for each dimension. The start value is the minimum value, and the step size is determined by a number of discrete bins in the integer type we are using.
In this example, we’ll be using 8-bit unsigned integers uint8_t and in uint8_t we have 8 bits of
0’s and 1’s that gets us to a total of 2^8 = 256 bins.
So the start is the minimum element entry in the list. As there are 256 steps we will take 255 steps to reach from start to stop i.e. (maximum to minimum).
And finally, our quantized dataset looks like something like this ➖
So the overall scalar quantization can be jammed together in a function like this:-
So this was a complete idea about scalar quantization.
Did you notice one thing? In Scalar quantization, we never took into account the distribution of data.
Let’s understand with an example what I meant here:-
Say we have a list of entries -
Array ➖
[ [ 8.2, 10.3, 290.1, 278.1, 310.3, 299.9, 308.7, 289.7, 300.1],
[ 0.1, 7.3, 8.9, 9.7, 6.9, 9.55, 8.1, 8.5, 8.99] ]
When we quantize the data ( to a 4-bit integer ) ->
4 bit integer: 2^4 = 16 bins
Data ➖
[ [ 8.2, 10.3, 290.1, 278.1, 310.3, 299.9, 308.7, 289.7, 300.1],
[ 0.1, 7.3, 8.9, 9.7, 6.9, 9.55, 8.1, 8.5, 8.99] ]
We get these results ➖
[ [16, 16, 16, 16, 14, 16, 15, 16, 16],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0] ]
and when we see what different bins we are putting our data in. We see all of our data for dimension 2 goes to 0, which is not a good thing as we will lose out on a lot of precious information because of this approximation.
That is the reason we switched to Product Quantization.
Let’s now jump into product quantization after reading why we need this form of quantization.
Steps for Product Quantization are ➖
Given a dataset for A vectors. Divide each vector into sub-vectors of dimension B.
( It is considered a good practice to take every sub-vector of the same length )
Now using k-means clustering on each sub-vector we’ll get k centroids each of which will be assigned a unique ID.
Now just replace each sub-vector with an ID of its nearest centroid.
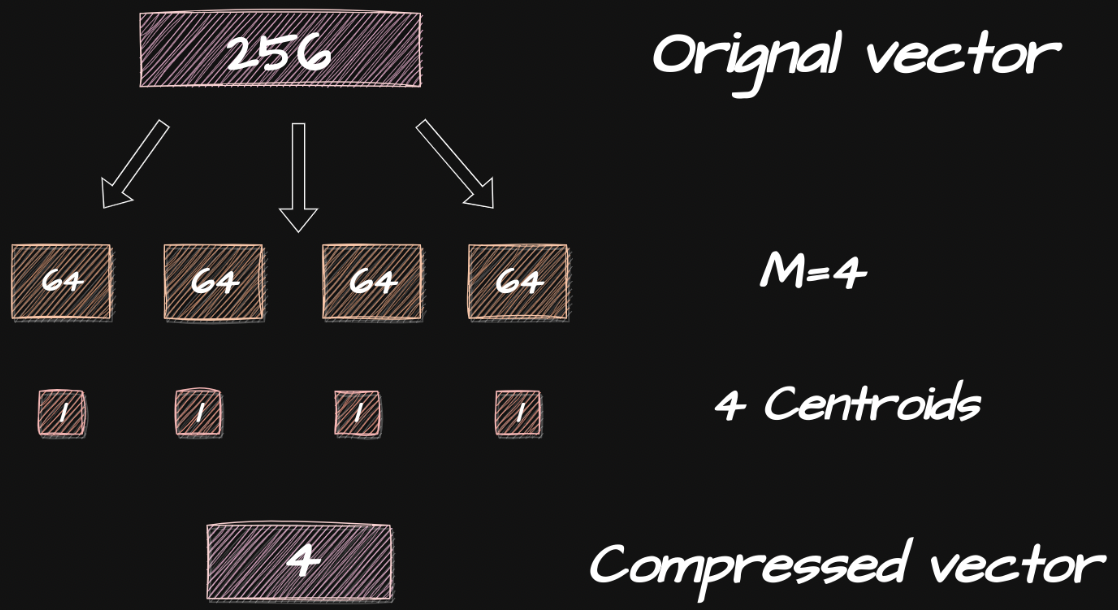
Product quantization can significantly reduce memory footprint and also speed up the nearest neighbor search but at the cost of a bit of accuracy. The tradeoff in Product Quantization is based on the number of centroids we use. The more centroids we use the better the accuracy but then the memory footprint would not be decreasing and vice versa.
Now the next question is: where can we apply them?
Simple answer - Quantize the model
But what is
Model quantization can reduce the memory footprint and computation needs of deep neural network models as model weights are nothing more than vectors so they can also be quantized and converted model weights from standard floating data type (i.e. 32-bit floats) to a lower precision data type (i.e 8-bit integers) thus saving memory and resulting in faster inference.
Let’s recap a technique to quantize a model that is QLORA which is an improvement over its predecessor LORA. LORA was made with a very basic thought that for fine-tuning a model we don’t have to re-tweak whole weight parameters but instead, we can add rank-decomposition weight matrices alongside our weights and will only train those small number of parameters.
QLORA is using 4-bit quantization under the hood for fine tuning an LLM. A small number of trainable adapters are added alongside frozen full weights for an LM which is just as LORA. During fine tuning, QLoRA backpropagates gradients through the frozen 4-bit quantized pre-trained language model into the Low-Rank Adapters.
But how is it different?
QLORA takes this same basic idea and moves to step further it introduces something called Double Quantization which is basically quantizing the Low Rank quantization constants which will eventually decrease the memory footprint to a further 0.37 bits per parameter, which is 3GB of memory for the 65B model.
So this is how models can be finetuned using QLORA.
So this kinda sums up the blog. Hope you enjoyed 🙂
In this blog, we have walked through
- What is quantization and why do we need quantization?
- What is Scalar quantization?
- Why do we switch from Scalar to Product quantization?
- How does Product Quantization work?
- What is Model quantization and how QLORA can be used?
About the authors
Sahib Singh
Data Scientist at Tatras Data
Experienced Data Scientist focusing on NLP, Conversational AI, and Generative AI. It is recognized as a top mentor on Kaggle, positioned in the uppermost 0.01% percentile. Adept at both collaborative teamwork and leadership, possessing outstanding communication proficiency.
Siddarth R
Lead Data Scientist at
Microsoft
Siddarth has 19 years experience across Tech and Healthcare. He currently works as Principal Data Science Manager at Microsoft. He is leading a team of data scientists and engineers to deliver strategies for optimization.


