
NLP - from Theory to Practice
Jul 25
/
Rupesh Keesaram & Siddarth R
Have you ever been curious about the inner workings of language models like ChatGPT and virtual assistants like Alexa? How do language models like ChatGPT and Alexa comprehend requests? Do you think they are equipped with extraordinary abilities that go beyond our understanding?
In this blog post, we’ll delve into the fascinating world of Natural Language Processing (NLP) and explore the mechanisms behind these powerful language processing technologies. However, before we dive into the intricacies of NLP, it’s crucial to understand its underlying concepts and techniques. Without a basic understanding of NLP, the pipeline may seem overwhelming, and it can be difficult to grasp how it works.
What is Natural Language Processing ( NLP )
Natural language processing (NLP) is a branch of artificial intelligence (AI) and computational linguistics that focuses on the interactions between computers and human language. NLP involves developing algorithms and techniques to enable computers to understand, interpret and generate human language in a way that is meaningful and useful.
If the above definition of NLP seems confusing, don’t worry! Let me explain it in simpler terms that everyone can understand.
NLP basically focuses on teaching computers to understand and interpret human language. In other terms, it’s a technology that allows computers to read, analyze, and interpret human language just like we do. For example, if you’re using a virtual assistant like Siri or Alexa to ask a question, NLP helps the computer understand your question and provide an appropriate response. Without NLP, computers would only be able to recognize and respond to specific commands or programmed responses.
Understanding Natural Language Processing (NLP) concepts and techniques
Components of NLP
Natural Language Processing (NLP) comprises two main components:
- Natural Language Understanding (NLU)
- Natural Language Generation (NLG)
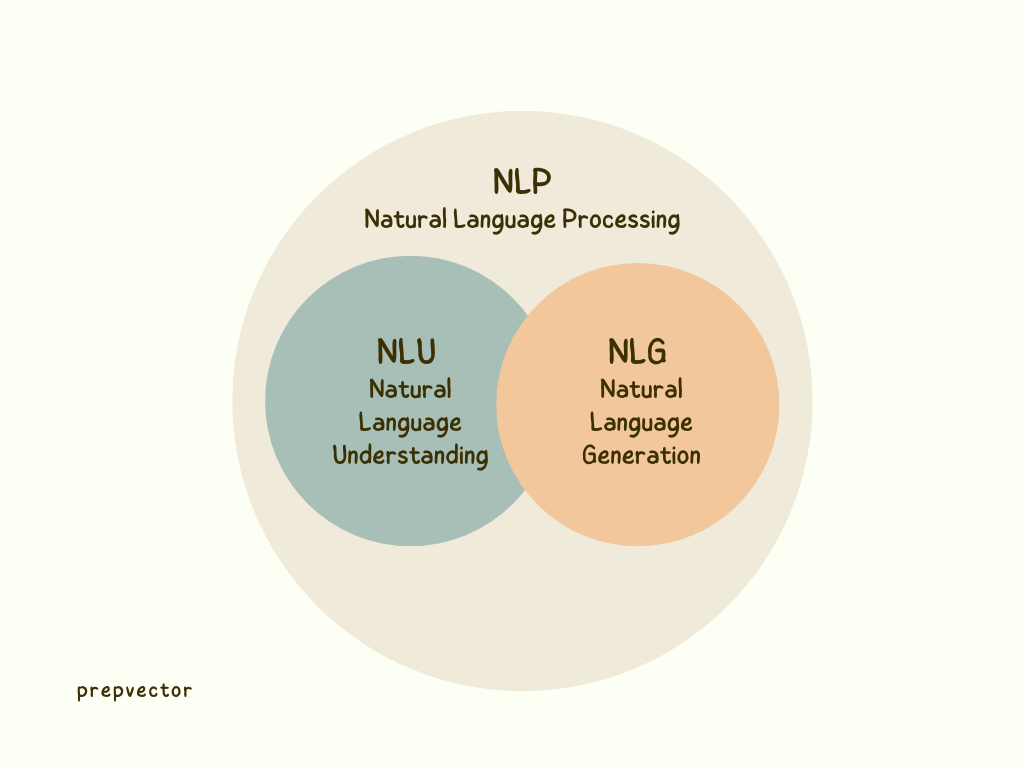
NLU focuses on converting human language like text and audio into structured data that can be analyzed and processed by computers to extract facts from them. For example, NLU can help extract key information from a product review or customer feedback, such as the sentiment, topics discussed, or important keywords. Some popular examples of NLU applications include sentiment analysis, named entity recognition, and text classification.
On the other hand, NLG is a vital component of chatbots and automated writing applications such as ChatGPT, which has become a recent trend in the tech industry. These systems use NLG to generate human-like responses based on user input, enabling them to converse with users in a natural and intuitive way.
With NLG, chatbots can provide personalized responses, answer questions, and even provide recommendations to users, making them an indispensable tool for businesses looking to improve their customer service and engagement.
With NLG, chatbots can provide personalized responses, answer questions, and even provide recommendations to users, making them an indispensable tool for businesses looking to improve their customer service and engagement.
Now that you have the basic understanding of NLP, and its different components, let’s explore the NLP process in detail.
A Buzz Word Called Pipeline
I know how furious you’ll get by seeing this step-by-step guide of Lays chips manufacturing in a tech blog like this, but hold it for a second, I put it on a purpose of introducing you folks to the word called pipeline.
Let’s delve into the NLP pipeline by drawing parallels with the intriguing process of manufacturing Lays potato chips. By examining the steps involved in creating Lays chips, we can gain an understanding of how an NLP pipeline functions.
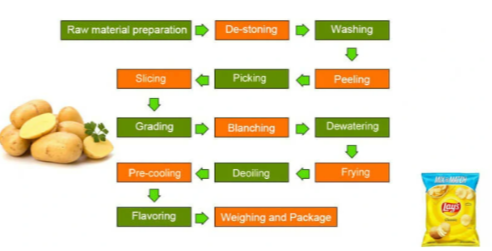
From sourcing the potatoes to adding the right flavors, there are several steps involved in creating this popular snack. Similarly, in Natural Language Processing (NLP), there is a similar concept called a pipeline that involves a series of steps to transform raw data into meaningful insights.
Now, let’s assume that the potatoes represent data, the flavors represent techniques, and the machinery represents the NLP pipeline or process. Initially, we start with raw data that needs to be processed and transformed to extract meaningful insights. This raw data is fed into the NLP pipeline, which applies a series of techniques or “flavors” to clean, tokenize, and analyze the data. Finally, the results are presented beautifully for further analysis or modeling.
In conclusion, just like the complex process of creating a pack of Lays chips involves several steps, the process of Natural Language Processing involves a similar pipeline approach. By breaking down the data processing into a series of steps and techniques, we can transform raw data into meaningful insights that can inform decisions and drive innovation. So, next time you enjoy a pack of Lays chips, remember the NLP pipeline that goes into making them so delicious!
Natural Language Processing Pipeline
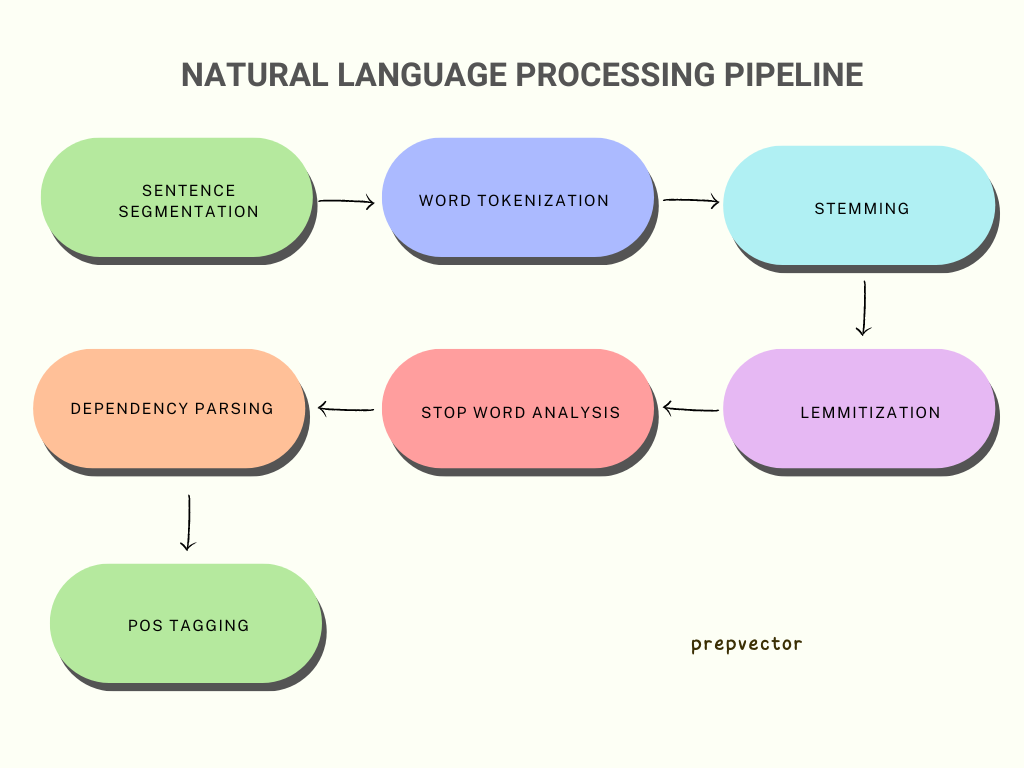
The NLP pipeline involves several steps that can vary depending on the application and the data involved. Some common steps include text cleaning, tokenization, part-of-speech tagging, entity recognition, and sentiment analysis. Each step adds a layer of processing that helps to extract relevant information and insights from the raw data.
Let’s dive a little bit deeper into each stage for better understanding of the process.
Let’s dive a little bit deeper into each stage for better understanding of the process.
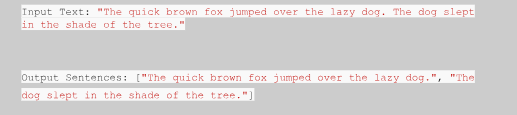
1. Sentence Segmentation
Sentence segmentation, also known as sentence boundary disambiguation, is a crucial task in Natural Language Processing (NLP). It involves identifying and separating individual sentences from a larger piece of text or document.
There are several ways to perform sentence segmentation, including rule-based approaches, statistical models, and machine learning techniques.
Rule-based approaches use predefined rules based on punctuation marks, such as periods, exclamation marks, and question marks, to identify sentence boundaries.
Statistical models and machine learning techniques use a combination of linguistic features, such as part-of-speech tagging and syntactic parsing, to identify sentence boundaries. We can consider NLTK and Spacy libraries for rule-based and statistical or machine learning-based techniques for sentence segmentation, respectively.
2. Word Tokenization
Word tokenization is the process of splitting a text into individual words or tokens. It’s a fundamental step in NLP and can be performed using whitespace or punctuation as delimiters. Word tokenization helps in standardizing text for further analysis, such as counting words or building models. It can also be used for more advanced tasks like named entity recognition or sentiment analysis.

3. Stemming
Stemming is the process of reducing a word to its base or root form, by removing any suffixes or prefixes. The goal of stemming is to normalize words so that variations of the same word can be treated as the same word, even if they appear in different forms.
For example, the word “running” has the stem “run”, and the word “jumps” has the stem “jump”.

4. Lemmatization
Lemmatization is the process of reducing a word to its base or dictionary form, known as the lemma. Unlike stemming, which simply removes suffixes and prefixes, lemmatization considers the context of the word and its part of speech in the sentence.
For example, the word “better” can be a comparative adjective or an adverb, but the lemma is “good”. Similarly, the word “mice” has the lemma “mouse”.

5. Stop Word Analysis
Stop word analysis is a technique used in NLP to remove commonly occurring words (such as “the”, “and”, “a”, etc.) from text data. These words are often referred to as stop words as they don’t add any value to the text analysis and can be safely ignored.
The stop word analysis is usually done as a preprocessing step before performing any NLP analysis, such as sentiment analysis or topic modeling. By removing the stop words, the remaining words in the text can provide more meaningful insights.
In the below example, the stop words “the”, “over”, and “a” have been removed from the input sentence, leaving only the relevant words “quick”, “brown”, “fox”, “jumps”, “lazy”, and “dog”.

6. Dependency Parsing
Dependency parsing is a natural language processing technique that analyzes the grammatical structure of a sentence by identifying the relationships between words. It involves identifying the main subject and the verb in a sentence and then mapping out the relationship between other words in the sentence with respect to these key elements.
For example, consider the sentence “The cat sat on the mat.” In this sentence, “cat” is the subject and “sat” is the verb. Dependency parsing would then analyze the relationships between “the,” “on,” and “mat” with respect to these key elements to create a tree-like structure that represents the sentence’s grammatical structure.

In this example, the verb “sat” is the root node of the tree, and “cat” and “mat” are its direct children, while “the” is a child of “cat”. The dependency parsing tree provides a visual representation of the relationships between the words in the sentence.
7. POS Tagging
Importance of POS tagging in understanding sentence structure
POS tagging, or part-of-speech tagging, is the process of labeling each word in a sentence with its corresponding part of speech, such as noun, verb, adjective, or adverb. This is an important task in natural language processing because it helps in understanding the meaning and grammatical structure of a sentence.
For example, consider the sentence: “The cat is sitting on the mat.” In POS tagging, each word would be labeled with its corresponding part of speech, as follows:

After performing POS tagging, the NLP pipeline moves on to the next stage, which involves applying syntactic and semantic analysis techniques to extract meaningful insights from the text. These techniques include named entity recognition, sentiment analysis, topic modeling, and more.
Named entity recognition involves identifying and classifying entities such as people, organizations, locations, and dates mentioned in the text. Sentiment analysis helps determine the overall sentiment of the text, whether it is positive, negative, or neutral. Topic modeling aims to identify topics or themes discussed in the text.
Although there are many challenges involved in implementing an NLP pipeline, it has enormous potential to revolutionize the way we process and analyze text data. In the upcoming blog, we will delve deeper into the practical implementation of the NLP pipeline using popular Python libraries such as NLTK, spaCy. Stay tuned for more!
If you are aspiring data scientist who wants to upscale or pivot into the tech field, we have the right mentors to guide you. Check out our course Product Data Science, and the benefits you get through enrollment!
About the Authors
Rupesh Keesaram,
NLP Enginner at Xformics
NLP Enginner at Xformics
Rupesh is an experienced NLP engineer skilled in text analysis, data-driven solutions, Credit Risk Modeling, sentiment analysis, and entity recognition. Passionate about staying up to date with the latest advancements in NLP. Collaborative team member with excellent communication skills. Committed to delivering high-quality solutions that unlock the value hidden within textual data.
Siddarth R
Lead Data Scientist at
Microsoft
Lead Data Scientist at
Microsoft
Siddarth has 19 years experience across Tech and Healthcare. He currently works as Principal Data Science Manager at Microsoft. He is leading a team of data scientists and engineers to deliver strategies for optimization.

Copyright © 2022
Contact Us!
Got a question? Reach out to us and we will get back to you ASAP!
Thank you!
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
By submitting this form, you consent to abide by the Privacy Policy outlined by PrepVector.
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
Access has ended, sorry.
But you can reach out to us at operations@prepvector.com if you need access to the giveaway.
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
By submitting this form, you consent to abide by the Privacy Policy outlined by PrepVector.
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
By submitting this form, you consent to abide by the Privacy Policy outlined by PrepVector.
Created with
