
Thinking in Vectors
Sep 13
/
Sahib Singh & Siddarth R
In the realm of modern data representation and retrieval, embeddings have emerged as a transformative technique. At their core, embeddings encapsulate complex entities such as words and sentences into compact vector representations, enabling machines to process and understand language with remarkable efficiency.
Word embeddings, a pioneering concept, map words to numerical vectors, capturing semantic relationships and contextual nuances. Sentence embeddings take this a step further, encoding entire sentences into vectors that encapsulate their meanings. The need for embeddings arises from the limitations of conventional databases in handling high-dimensional and semantic data.
Word embeddings, a pioneering concept, map words to numerical vectors, capturing semantic relationships and contextual nuances. Sentence embeddings take this a step further, encoding entire sentences into vectors that encapsulate their meanings. The need for embeddings arises from the limitations of conventional databases in handling high-dimensional and semantic data.
This blog delves into the world of embeddings, dissecting their significance in overcoming these challenges. Furthermore, it explores the advent of vector databases, purpose-built systems designed to manage embeddings, and high-dimensional data. With a focus on indexing, the blog uncovers how vector databases efficiently organize and retrieve information from vast vector spaces, introducing the concept of Inverted File Systems (IVF) as a key indexing technique. As we traverse the landscape of embeddings, word and sentence representations, vector databases, and IVF, we unravel the intricate threads of modern data management that empower AI and NLP applications to bridge the gap between human language and machine understanding.
Topics to be covered in this Blog
- What are embeddings?
- What are word embeddings?
- What are sentence embeddings?
- Why are they required and why don't conventional DB’s don’t work?
- What are vector databases?
- What is indexing in Vector Databases?
- What is IVF?
What are embeddings?
Ok, the first big question is what are embeddings? Just for the time try to see it as embeddings are jumbers assigned to words in a text.
Don’t worry, I’ll explain it further. 🙂
Q - The second question should be why we are using embeddings.
A - We are using embeddings just because machines don’t understand the text as it is, and the text should be converted to numbers so that Machine Learning algorithms can crunch these numbers and make meaningful predictions.
A - We are using embeddings just because machines don’t understand the text as it is, and the text should be converted to numbers so that Machine Learning algorithms can crunch these numbers and make meaningful predictions.
Example
Say we Have 10 words ➖
- Cricket
- Hockey
- Football
- Cereal
- Iphone
- Banana
- Biscuits
- Pyramids
- Taj Mahal
- Eiffel tower
Now, if we project these words (i.e create embeddings) in a 2D space based on their properties they would look like the image below:
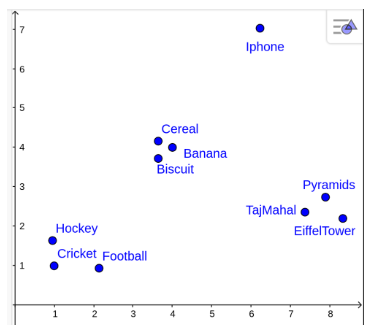
And now if we see the words Hockey, Cricket, and Football when represented in a 2D space are clubbed together because they have similar properties such as:
So these are the common properties that combine them.
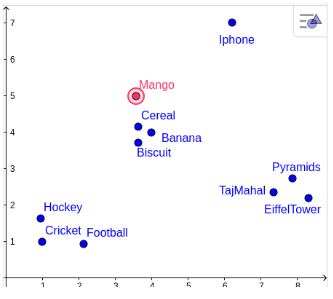
But the bigger question here is, where will I put my new word Mango? Ideally, it should be in the group of fruits and not in any other subgroup. Now, this is when we call any embeddings good when they can extract latent features of a word and club similar words together, and dissimilar words in other groups.
HEY THAT'S SO COOL
But hold on, we humans can only see things in 3 dimensions so it should not mean that our embeddings can have only 3 dimensions. So, that's the reason why we see embeddings of 384,512,1536 dimensions, etc.
So our Mango would fit in like this ➖
- All of them are outdoor sports.
- They are not individual events, etc.
So these are the common properties that combine them.
Similarly, words like Taj Mahal, Eiffel Tower, and Pyramids can be seen together when represented in a 2D space because they also share some common properties such as:
- All of them are ancient monuments.
- All of them are huge tourist attractions, etc.
But the bigger question here is, where will I put my new word Mango? Ideally, it should be in the group of fruits and not in any other subgroup. Now, this is when we call any embeddings good when they can extract latent features of a word and club similar words together, and dissimilar words in other groups.
HEY THAT'S SO COOL
But hold on, we humans can only see things in 3 dimensions so it should not mean that our embeddings can have only 3 dimensions. So, that's the reason why we see embeddings of 384,512,1536 dimensions, etc.
So our Mango would fit in like this ➖
So in short, we can say word embeddings are just Numbers assigned to a word but they are assigned in such a way that Machine learning algorithms can generate meaningful information out of the textual data.
Let’s push the envelope.
Let’s push the envelope.
What are embeddings?
Sentence embeddings are also similar to word embeddings where the goal is that we have to provide a vector representation to a sentence.
Now, the first approach that comes to mind for assigning a vector representation to a sentence is: Assign the average of all word vectors to make sentence embeddings, i.e., say we have a sentence
“ Yes, you are fine” and “Are you fine. Yes”
Both the sentences are different as the first one is telling something but the second one is asking a question.
If we would have taken the Avg. representation approach. The sentence embeddings would have been the same for both, which is not a good sign.
So, this is how we say one sentence embedding is better than the other, i.e The model we used for creating sentence embeddings can develop different embeddings for similar-looking sentences, or extreme cases can create different embeddings for 2 sentences whose words are the same but just that the order of words is different.
Now let’s address a hot keyword these days. i.e, VECTOR DATABASES
But before, let’s understand why we need these databases given we have conventional relational databases.
The biggest point that we have to keep in mind is that these databases are used to store embeddings and embeddings themselves are just floating point numbers and there will never be a situation where a user will get an exact match the way we used to get when we are using relational databases.
Now, the first approach that comes to mind for assigning a vector representation to a sentence is: Assign the average of all word vectors to make sentence embeddings, i.e., say we have a sentence
“ Yes, you are fine” and “Are you fine. Yes”
Both the sentences are different as the first one is telling something but the second one is asking a question.
If we would have taken the Avg. representation approach. The sentence embeddings would have been the same for both, which is not a good sign.
So, this is how we say one sentence embedding is better than the other, i.e The model we used for creating sentence embeddings can develop different embeddings for similar-looking sentences, or extreme cases can create different embeddings for 2 sentences whose words are the same but just that the order of words is different.
Until now, we have covered the concepts: what are embeddings, what are vectors and what are sentence embeddings?
Now let’s address a hot keyword these days. i.e, VECTOR DATABASES
But before, let’s understand why we need these databases given we have conventional relational databases.
The biggest point that we have to keep in mind is that these databases are used to store embeddings and embeddings themselves are just floating point numbers and there will never be a situation where a user will get an exact match the way we used to get when we are using relational databases.
Why conventional DB’s don’t work?
Let’s take an example:
Say, we have a Vector Database having embeddings of 1500 words and our goal is to find a bunch of words. Say we have to find words like Apple, Banana, Mango, Pineapple, etc.
Now. we cannot directly use SQL commands to filter out these embeddings because if we look at these embeddings from a 10,000 m view. It would look like the embeddings of all these similar words are just random floating numbers. So, that's why these conventional Relational Databases don’t work efficiently for our system.
VECTOR DATABASES
These are databases that are specifically used for storing embeddings and when we say embeddings we are not confined to Text embeddings they can be embeddings for images and audio as well these databases employ a special set of algorithms to search data and the family of algorithms is called ANN ( Approximate Nearest neighbors ) which is different from KNN ( k Nearest neighbors ).
Let's now delve into the reasons why vector databases are special and emerge as the ultimate solution:
1. Effortless Data Management: Vector databases bring forth a spectrum of user-friendly data management features. From effortless data insertion, and deletion, to seamless updates, handling vector data becomes a breeze. Unlike standalone vector indices like FAISS, where integration with storage solutions can be complex, vector databases simplify the process.
2. Empowering Metadata Handling: One of the standout features of vector databases is their ability to store metadata alongside vector entries. This opens the door to enriched queries using metadata filters, enabling users to fine-tune their search results with precision.
3. Unparalleled Scalability: The scalability of vector databases is a game-changer. As data volumes swell and user demands rise, these databases effortlessly adapt, facilitating distributed and parallel processing. Standalone vector indices might require customized solutions, such as Kubernetes cluster deployment, to match this level of scalability.
In short, Vector Databases offer a comprehensive solution to cater to needs as compared to vector indices.
And, what is the difference between Vector Index and Vector Databases?
In the realm of search and retrieval for vector embeddings, the spotlight shines on FAISS (Facebook AI Similarity Search) and its prowess. However, it's essential to acknowledge that while FAISS, like standalone vector indices, can greatly enhance search efficiency, it operates within its limitations.
Let's now delve into the reasons why vector databases are special and emerge as the ultimate solution:
1. Effortless Data Management: Vector databases bring forth a spectrum of user-friendly data management features. From effortless data insertion, and deletion, to seamless updates, handling vector data becomes a breeze. Unlike standalone vector indices like FAISS, where integration with storage solutions can be complex, vector databases simplify the process.
2. Empowering Metadata Handling: One of the standout features of vector databases is their ability to store metadata alongside vector entries. This opens the door to enriched queries using metadata filters, enabling users to fine-tune their search results with precision.
3. Unparalleled Scalability: The scalability of vector databases is a game-changer. As data volumes swell and user demands rise, these databases effortlessly adapt, facilitating distributed and parallel processing. Standalone vector indices might require customized solutions, such as Kubernetes cluster deployment, to match this level of scalability.
4. Security of Data: Vector databases offer in-built data security options which otherwise which lack when we are using vector indices
In short, Vector Databases offer a comprehensive solution to cater to needs as compared to vector indices.
What is Indexing
Indexing is the process of creating data structures known as indexes, which enable efficient searching for vectors by quickly reducing the search space. This is how data is stored in a vector database. The embedding models used typically have vectors with a dimensionality of 10^2 or 10^3, and Approximate Nearest Neighbor (ANN) algorithms try to capture the true complexity of the data as efficiently as possible in terms of time and space.
There are many indexing algorithms available used in various DB’s like:-
So give a broader view this is how things are working under the hood.
There are many indexing algorithms available used in various DB’s like:-
- Inverted file Index
- Hierarchical Navigable Small World (HNSW) graphs
- Vamana
So give a broader view this is how things are working under the hood.
credits: https://www.pinecone.io/learn/vector-database/
Now let’s understand IVF, one of the Indexing techniques.
Inverted File Index (IVF)
Perfect as we have now understood the basic concept of Indexing and how it is the HEART of vector databases. Now, before diving into IVF let’s understand Flat indexing.
Flat Indexing or we call it in general terms “Linear Search“ where we don’t do any pre-processing to a vector and just use a query vector to find the nearest vectors available in the vector DB.
It goes in this way :
In the first two Lines, we created one query vector and one dataset of 1000 entries. In the third line, we searched for finding the most similar elements (having the least distance) from 1000 vectors in the database. This method is the most accurate but comes at the cost of time required because as the dataset gets bigger Query Per Second (QPS) starts to increase drastically.
The below table would explain it better:
The below table would explain it better:
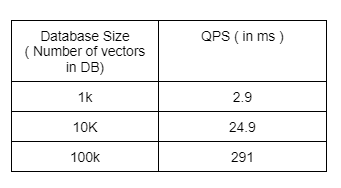
If we now observe the table we can see just for 100k vectors database and one query vector it took 291ms which is a 100 times increase in query time for one vector and if we have say 10k similar operations to perform we would be losing out on a lot of time.
The only issue we face with Flat indexing is the Lack of Scaling capabilities.
By making a slight sacrifice in accuracy and recall, we can achieve substantial enhancements in query speed and throughput. Amidst the multitude of existing indexing strategies, a prevalent one is known as the inverted file index (IVF).
Beyond its sophisticated label, IVF brings a rather straightforward concept. It streamlines the search process by segmenting the complete dataset into partitions, each linked with a centroid. Consequently, every vector within the dataset is allocated to a partition aligning with its closest centroid.

2D Voronoi diagram. Image by Balu Ertl, CC BY-SA 4.0
This type of diagram is called the Voronoi Diagram. This diagram tells that all the points in the dataset were clustered and we put them into 20 different regions and every region has one centroid.
Cluster centroids can be made using a variety of algorithms like k means etc. K-means represents an iterative algorithm that commences by the random selection of K points to serve as initial clusters and with every iteration points are assigned to their nearest cluster centroids
Now using the same knowledge we will sector out our dataset in K partitions and then we will look for the nearest centroid to our query vector and once we get to the nearest centroid say that centroid is named as centroid A for partition A.
Now we will look for the most similar vectors in partition A for our query vector and once we get the nearest set of vectors for our query vector our work is done. 🙂
The benefits of IVF:
- Instead of doing a flat search we first found the nearest Centroid to our query Vector.
- And once we find the nearest centroid we are looking for the most similar vectors in that corresponding cluster.
- As a result faster and more QPS is possible on the same machine.
The code for IVF is below.
This concludes this blog. We hope you like it 🙂
About the Authors
Sahib Singh
Data Scientist at Tatras Data
Data Scientist at Tatras Data
Experienced Data Scientist focusing on NLP, Conversational AI, and Generative AI. It is recognized as a top mentor on Kaggle, positioned in the uppermost 0.01% percentile. Adept at both collaborative teamwork and leadership, possessing outstanding communication proficiency.
Siddarth R
Lead Data Scientist at
Microsoft
Lead Data Scientist at
Microsoft
Siddarth has 19 years experience across Tech and Healthcare. He currently works as Principal Data Science Manager at Microsoft. He is leading a team of data scientists and engineers to deliver strategies for optimization.

Copyright © 2022
Contact Us!
Got a question? Reach out to us and we will get back to you ASAP!
Thank you!
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
By submitting this form, you consent to abide by the Privacy Policy outlined by PrepVector.
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
Access has ended, sorry.
But you can reach out to us at operations@prepvector.com if you need access to the giveaway.
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
By submitting this form, you consent to abide by the Privacy Policy outlined by PrepVector.
One more step!
Just a few details before you can download the resources.
Thank you!
Download your resource here
Download your resource here
By submitting this form, you consent to abide by the Privacy Policy outlined by PrepVector.
Created with
